注释
#开始的单行注释
“”“ 多行注释 “”“
”’ 多行注释 ‘”
for循环
for 变量 in 可迭代对象 :
代码
想要计数,必须借助于range
range(n): 从0数到n,但不包含n。
range(m,n): 从m数到n,但不包含n。
range(m,n,s): 从m数到n,但不包含n,间隔是s。
平时用的多的是for循环,while循环用的多的是死循环。
数据类型
int,float,bool
int:整数,加减乘除,大小比较
float:小数,浮点数 print(10/3) 3.33333333333335. 表示小数是会有误差的。
bool:用来做条件判断,取值范围只有两个true,false.
基础数据类型之间的转化:
a=”10″ #字符串
print(type(a))
b=int(a) #把字符串转化成int
a=10 #在python中,所有非零的数字都是true,0是fasle
b=bool(a)
print(type(b))
print(b) #true
s=”” #在python中,所有的非空字符串都是True,空字符串是False
#综上,在python的基本数据类型中,表示空的东西都是False,不空的东西是True
str(*****)
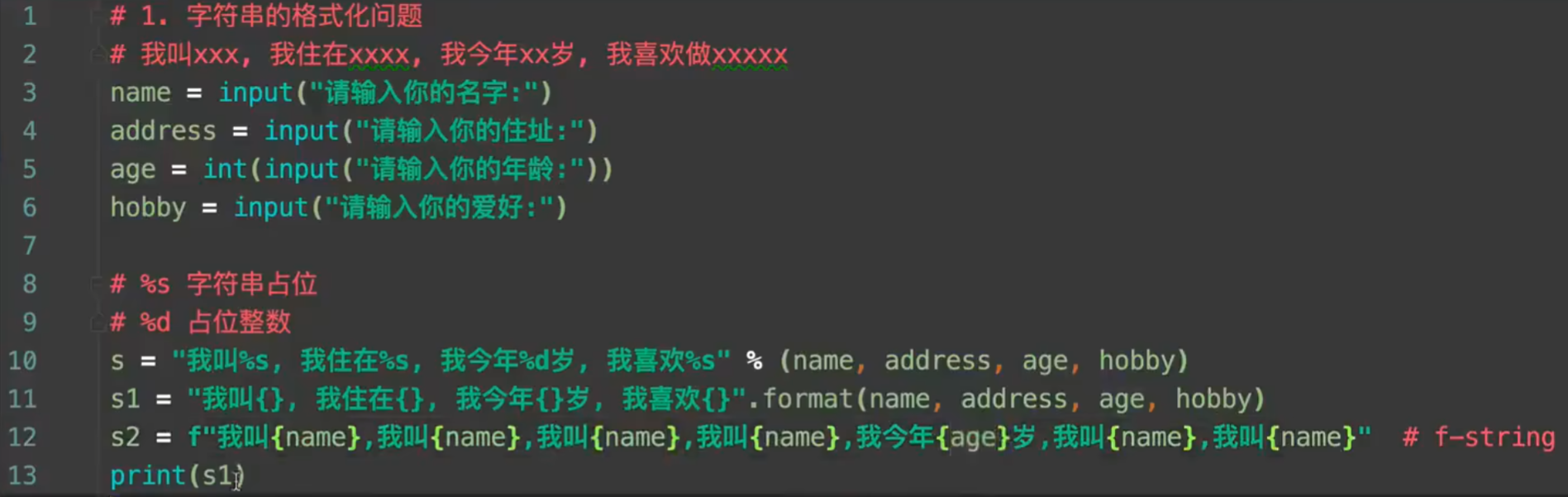



3.1字符串常规操作:
s.capitalize():首字母大写
s.title():每个单词首字母大写
s.lower():全改为小写
s.upper():全改为大写
3.2替换与切割:
strip(): 去除左右两端空白符(空格、\t、\n),中间不处理。s.strip()
replace(old,new)
split(用什么切换):字符串切割
a=”python_java_c_c#_javascript”
lst=a.split(“_”) #切割之后的结果会放在列表当中
3.3查找和判断
s.find() #返回数字位置,-1表示没有找到
s.index() #如果报错,表示没有
print(“周润发” in s) #in 可以做条件上的判断 not in 判断不存在
s.startwith(): #判断是否以什么开头
s.endwith(): #判断是否以什么结尾
s.isdigit(): #判断是否由整数组成
s.isdecimal()
补充:
len():
join(): #跟split()对应
list(*****)列表:
能装东西的东西。用[]来表示一个列表,元素之间用逗号隔开。
特性:
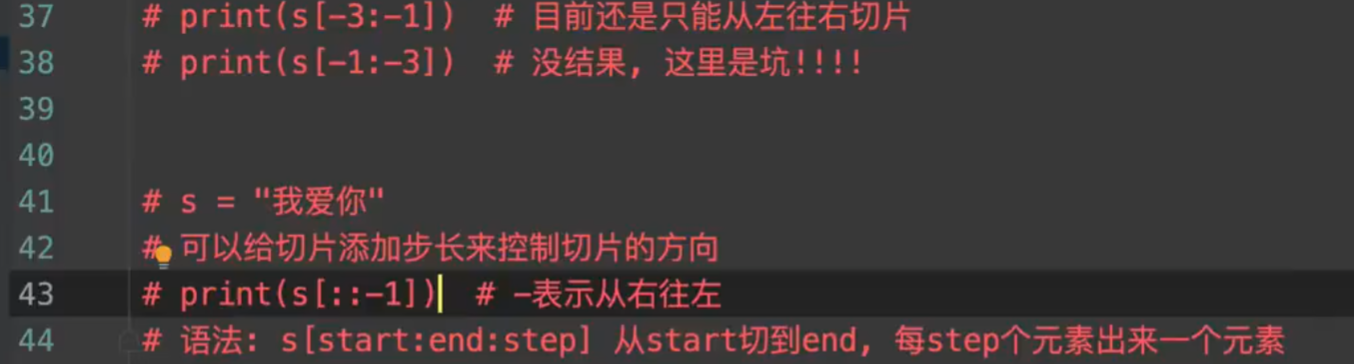
1,也像字符串一样有索引和切片。
2.列表的索引如果超过范围会报错,字符串也这样。
3.可以用for 循环遍历:两种方式 for item in list; for i in range(len(list)
4.用len()函数拿到列表的长度。
增删改查:
list.append():添加元素,追加
list.insert(0,”abc”): 在0个位置添加元素,其余元素往后顺延,效率低。
list.extend([‘武则天’,’赢政’,”马超’]) #批量添加ret = lst.pop(index) #删除第index个元素,返回被删元素。
lst.remove(item) #删除item元素,不返回值
lst[4]=newItem; #修改第4个元素,直接用索引修改
lst[index] #直接用index进行查询操作
排序:
列表会按照存放的顺序来保存。
lst.sort(): 对列表进行升序排序
lst.sort(reverse=True) #降序排序
列表的嵌套:
列表的循环删除:将要删除的内容保存在一个新列表中,循环新列表,删除老列表。
tuple(**)元组:
不可变的列表。固定了某些数据,不允许外界修改。
t=(“张无忌”,”赵敏”,“呵呵哒”)
元素如果只有一个元组,如t=(“哈哈”),这样会被默认解释为优先级运算。可改为t=(“哈哈”,)。多加一个逗号。
元组的不可变,但是其内部元素可以变。如
t=(1,2,3,[“呵呵哒”,“么么哒”]),但是可以t[3].append(“哒哒哒”)。
set(*)集合:
内部是无序的;不可放list。set类型用的不多。
不可哈希:python中的set集合进行数据存储时,需要对数据进行哈希计算,根据计算出来的哈希值进行存储数据,set集合要求存储的数据必须都是可以进行哈希计算的。可哈希的数据类型,不可变的数据类型,int, str, bool,tuple. 可变的数据类型如list,dict,set都不可哈希。
s={1,2,3}
set=set() #创建空集合
set.add():#添加元素
set.pop(): 不能放索引,由于集合无序,删除的比较随机,
set.remove(value):
想要修改,则先删除,再新增。
查询则用for 循环。
交集:s1 & s2 、 s1.intersection(s2)
并集:s2|s2 s1.union(s2)
差集: s1-s2 s1.difference(s2)
去重操作:集合当中不能有重复
lst=[‘周杰伦’,’昆凌’,’蔡依林’,’周杰伦’,’昆凌’]
print(list(set(lst))) #去除重复后是无序的。
dict(*****)字典:
字典是以键值对的形式存储数据的。字典的表示方式:{key:value,key2:value2, key3:value3}
val = dic[“key”]
字典的key必须是可哈希的数据类型,value可以是任何数据类型。
字典的增删改查:
dic=dict();
dic[‘jay’]=”周杰伦”;
dic[1]=123;
dic.setdefault(“tom”,”胡辣汤”); #设置默认值
dic.pop(key); #根据key删除
del dic[key]
查询: dic[key] 如果key不存在,会报错。 或者 dic.get(key’),如果key不存在,则返回None,不报错。
None:空。NoneType。python关键字。
字典中不能有重复的key.
1.可以用for循环,直接拿到key.
for key in dic:
2.dic.keys():拿到所有的key.返回dict_keys类型。可以用list(dist.keys())转化成列表。
3.dic.values():
4.直接拿到字典中的key和value dic.items();
a,b=(1,2) #元素或者列表都可以执行该操作,称为解构(解包),左右两边值的数量要相等。
for key,value in dic.items()
bytes(****):
s=“周杰伦”
bs1=s.encode(“gbk”)
print(bs1) # b’\xd6\xdc\xdb\xdc\xc2\xd7′ bytes类型
bs1=s.encode(“utf-8”)
print(bs1) # b’\xe5\x91\xa8\xe6\x9d\xb0\x34\xbc\xa6′
程序员平时遇见的所有数据最终单位都是字节byte。
怎么把一个gbk的字节转化成utf-8的字节
bs= b’\xd6\xdc\xdb\xdc\xc2\xd7′ #字节码
s=bs.decode(“gbk”) #解码
bs2=s.encode(“utf-8”) #重新编码
运算符(***)
文件操作(****)
函数
函数的概念
对某一特定的功能或者代码块进行封装,在需要使用该功能的时候直接调用即可。让代码更简介、合理、方便、简单。

函数的参数:
形参,以函数定义的时候,需要准备一些变量来接收信息。
1.位置参数:按照位置一个个的声明变量。
2.默认值参数:在函数声明时给变量一个默认值,需要放在位置参数后面。
形参,实际在调用的时候传递的信息。
1.位置参数:按时位置进行传递参数。
2.关键字参数,按照参数的名字进行传递参数。
3.混合参数:位置参数放前面,关键字参数放后面,
4.动态传参:
eg :*args,表示所有位置参数的动态传参。 *接收到的值会被统一放在一个元组里面。
**kwargs:表示关键字参数的动态传参,接收到的所有参数都会被处理成字典。
形参在执行时,必须有值,否则报错。实参在执行的时候,必须保证形参有数据。
混用时的顺序:位置参数>*args>默认值>**kwargs
列表作为参数:
stu_list=[‘a’,’b’,’c’,’d’,’e’];
func(*stu_list)
func(**stu_dict): 将字典打散为关键字参数
函数的返回值:程序执行到return,函数就会立即停止执行并返回内容,函数内return后面的语句不会再执行。
如果函数内没有return ,默认返回None;
写了return, 只写了return,后面没跟值,返回None。
return 后面接一个值。
return 后面接多个值,此时函数返回多个值,外界接收到的是元组,该元组内存放所有的返回值。
python内置函数
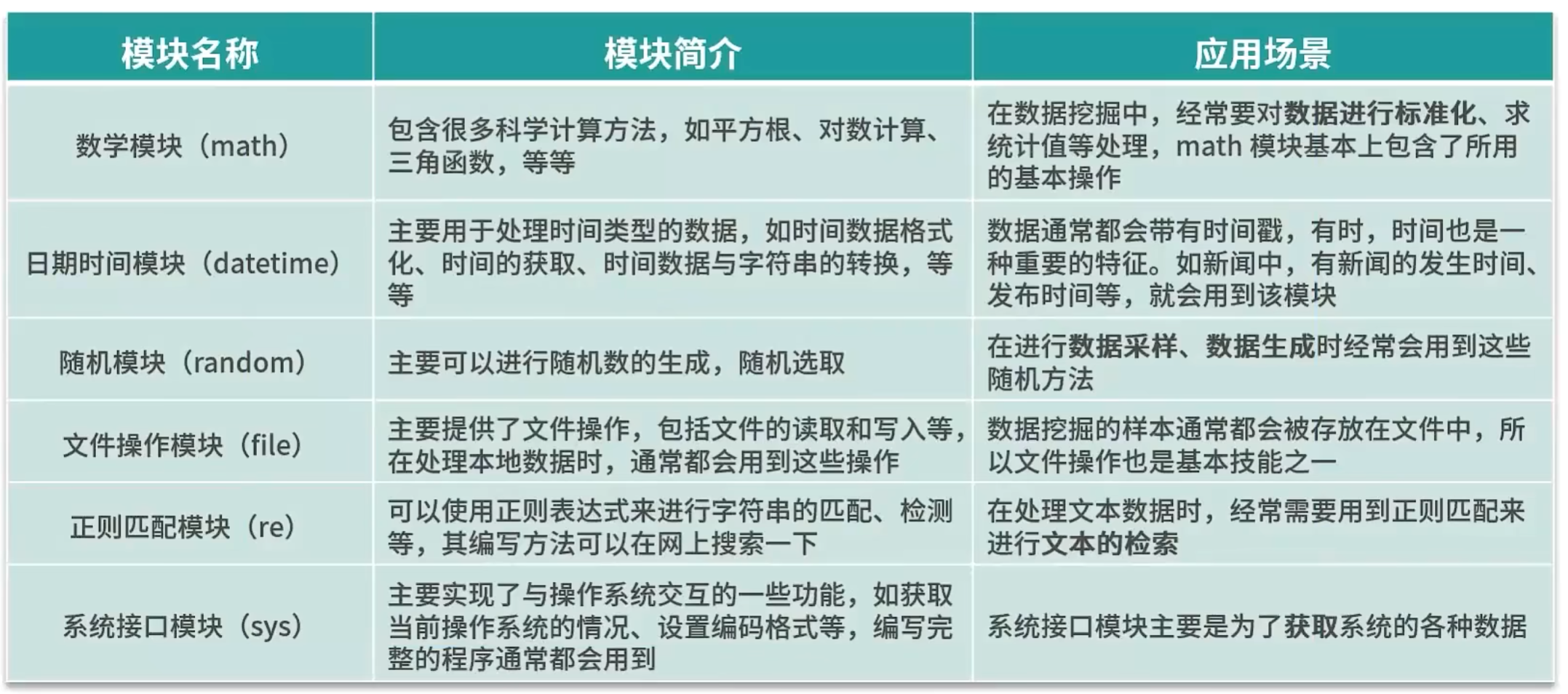
标准库:
Python的标准库是其核心的扩展,包括操作系统接口、文件操作、输入输出流、文本处理等功能。
dir() #查看模块中所包含的工具
help() #展示模块中所有方法的说明


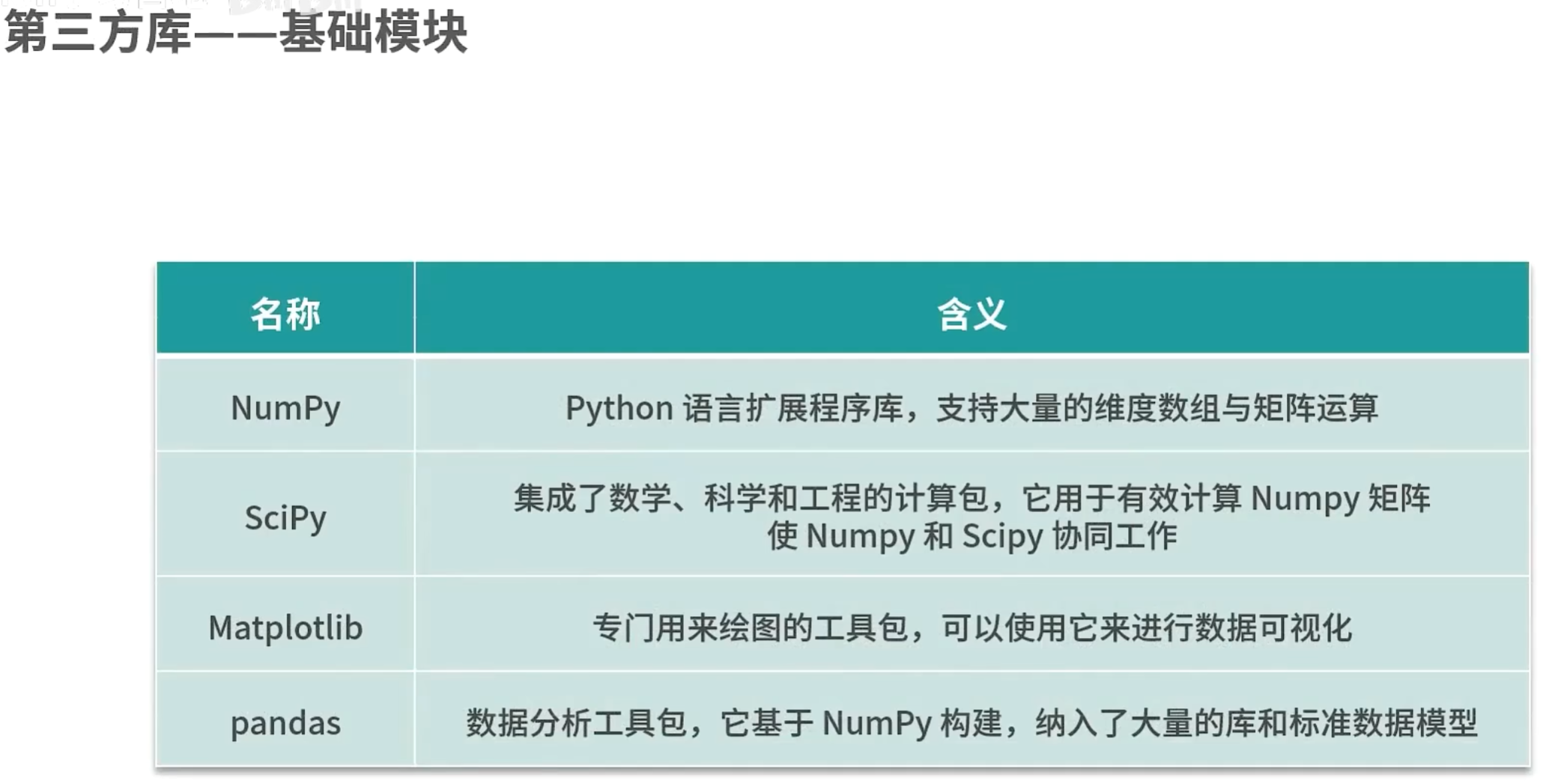

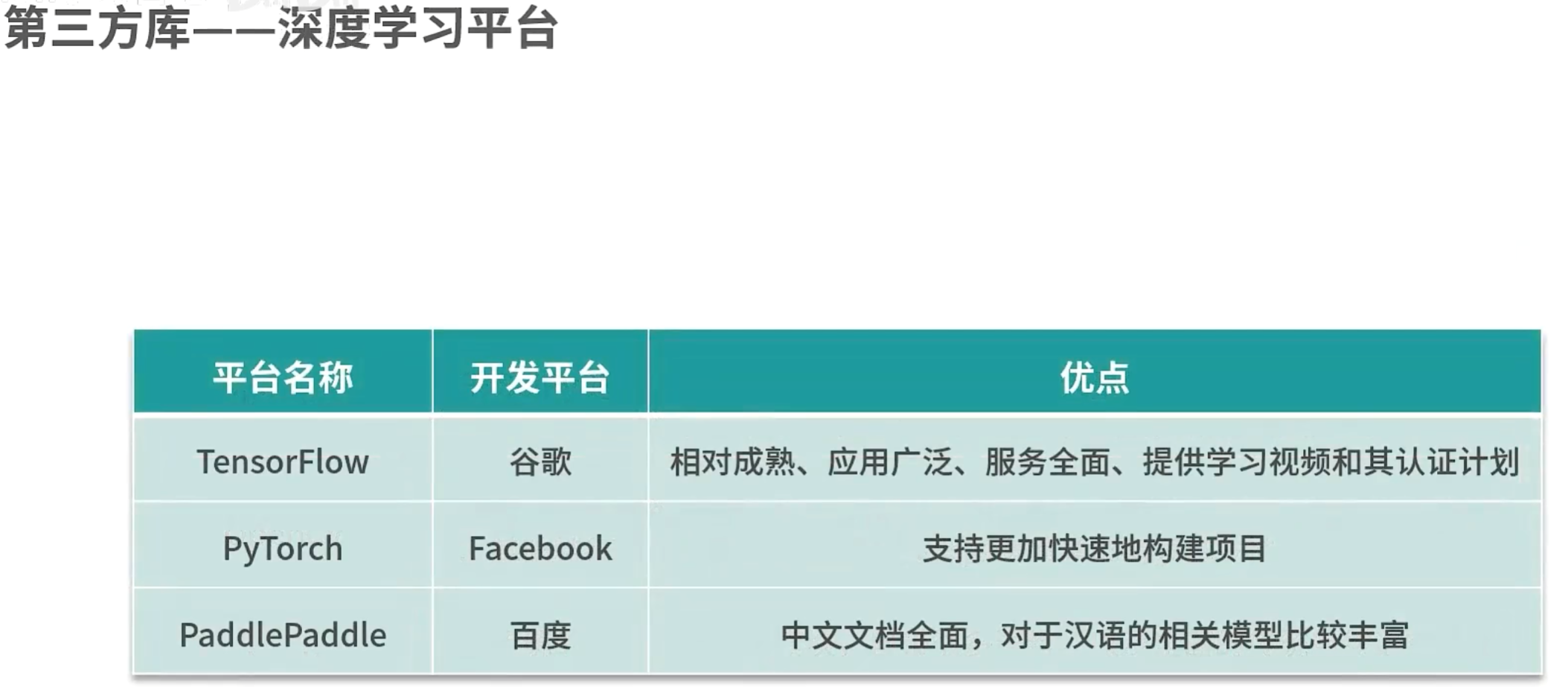
使用pip安装扩展包:
使用pip可以对Python扩展包进行查找、下载、安装、卸载等。python3.6后,已是自带安装
pip –version #查看pip是否已经安装
pip install -U pip #升级pip到最新版
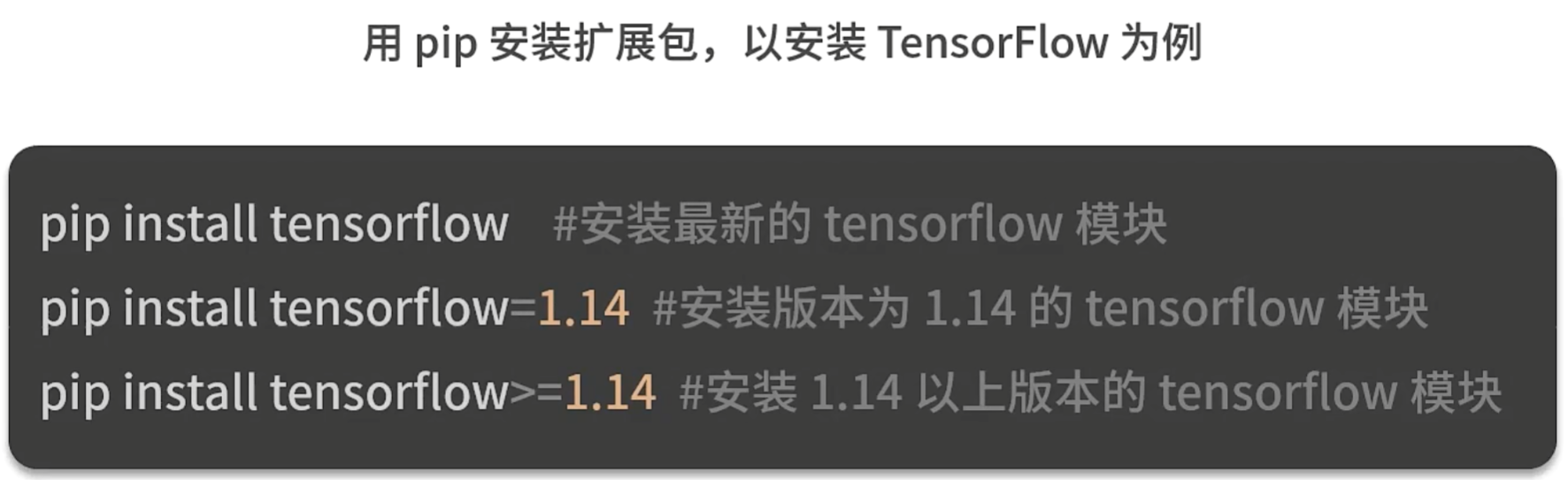
pip uninstall tensorflow #用pip卸载某个模块
pip search tensorflow #在pip库中搜索某个模块
pip list #用pip显示已安装的包
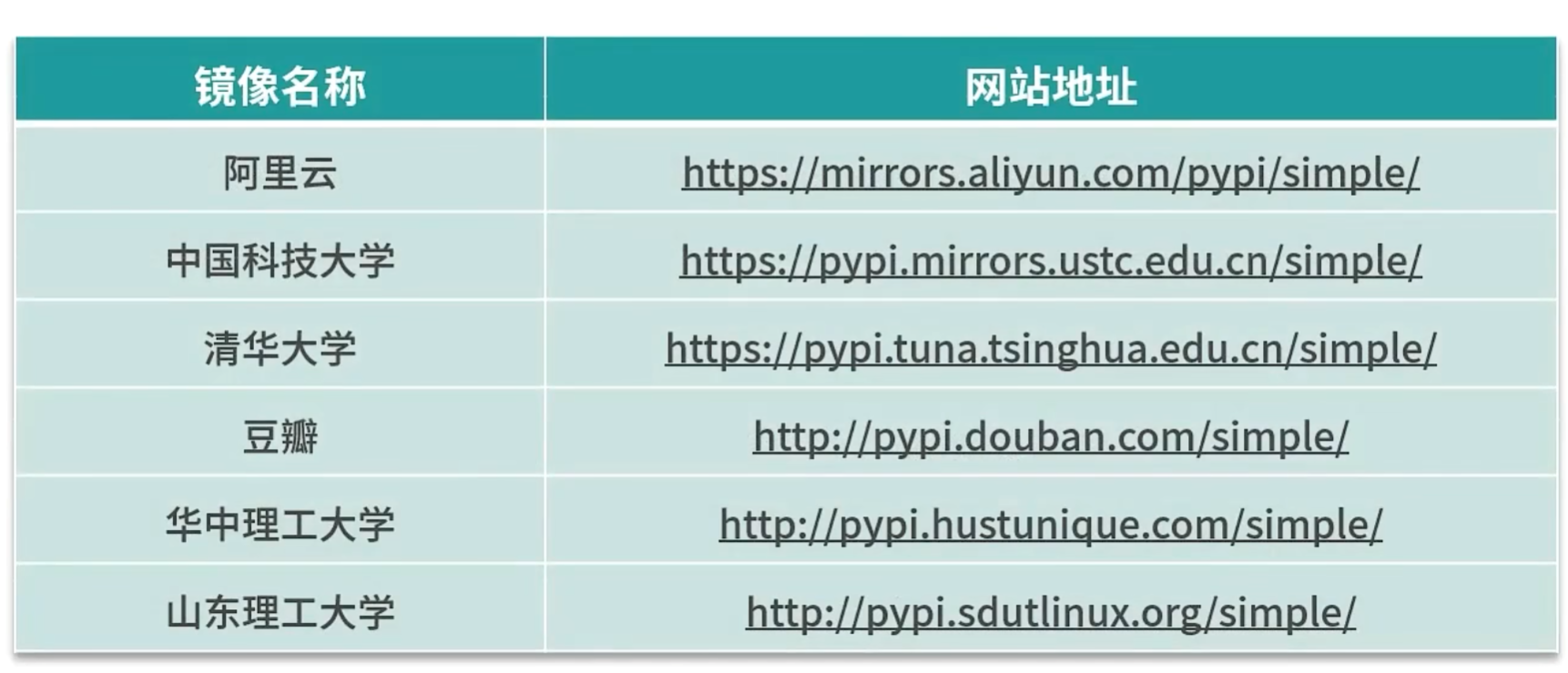
pip install tensorflow -i https://pypi.tuna.tsinghua.edu.cn/simple #注意是一行代码,切换镜像源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple #注意这是一行代码,用pip更新配置文件,修改默认源









分类问题:
二分类:要回答的问题只有“是”或“否”。
多分类:在二分类的基础上,将标签可选范围扩大。
多标签分类:多标签分类下的一条数据可以被标注上多个标签。
KNN算法、决策树算法、随机森林、SVN等,都是为解决分类问题设计的。
聚类问题:
聚类是无监督的,如在一个旅游APP上有上千万的用户, 你可能会需要把用户划分成若干个组,以便针对特定的用户群体去开发一些特定的功能。
聚类是把一个数据集划分成多个组的过程,使得组内的数据尽量高度集中,和其他组的数据之间尽量远离。



回归问题:
分类方法输出的是离散的标签。回归方法输出的结果是连续值。




关联问题:

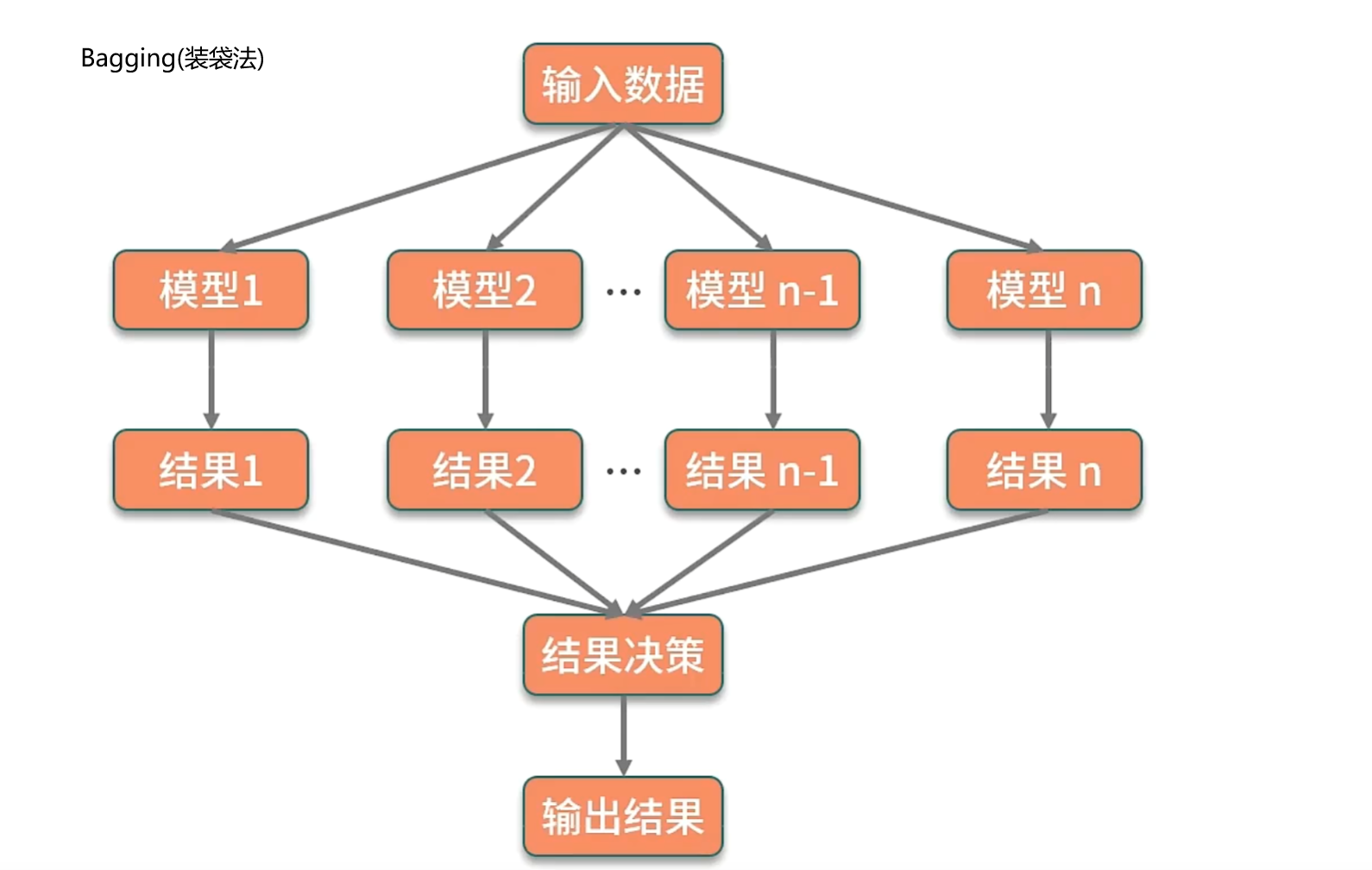
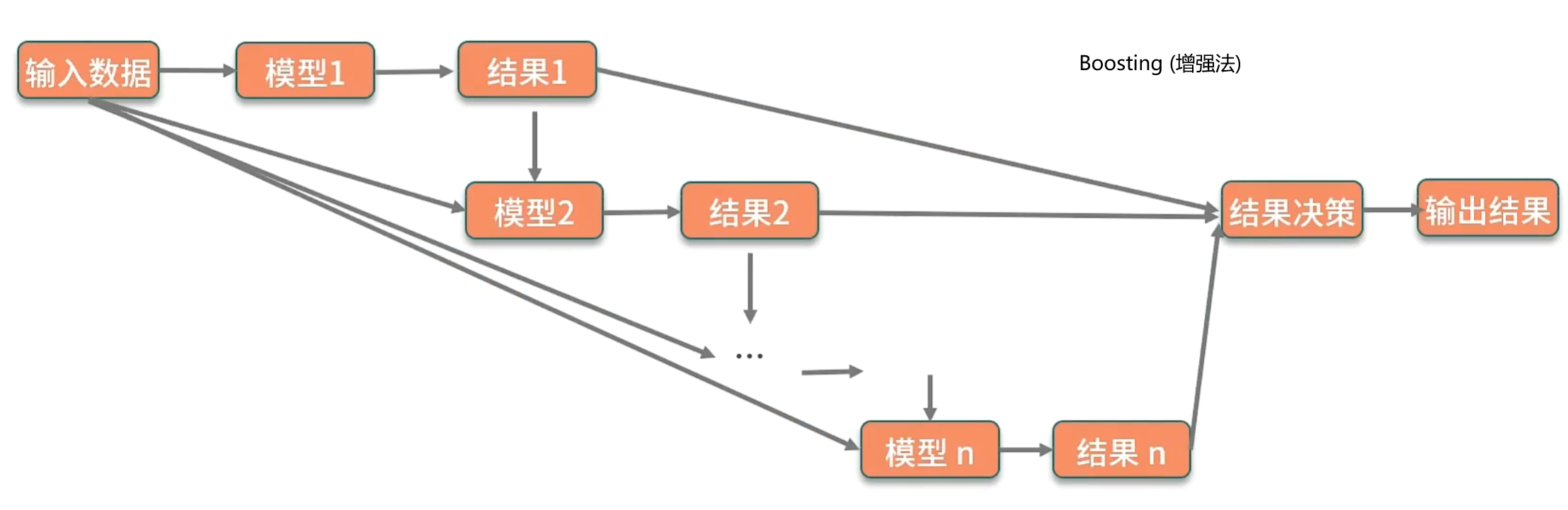
模型集成:
模型集成也可以叫做集成学习。思路:合并多个模型来提升整体的效果。

KNN算法:近朱者赤,近墨者黑
算法原理:找到K个与新数据最近的样本,取样本中最多的一个类别作为新数据的类别。
欧式距离:两点之间的连线。
优点:简单易实现; 对于边界不规则的数据效果较好;
缺点:只适合小数据集; 数据不平衡效果不好;必须要做数据标准化;不适合特征维度太多的数据。
关于K值的选择:K值的选取会影响到模型的效果。K越小的时候容易过拟合,K越大的时侯容易欠拟合。合适的K值需要根据经验和效果去进行尝试。



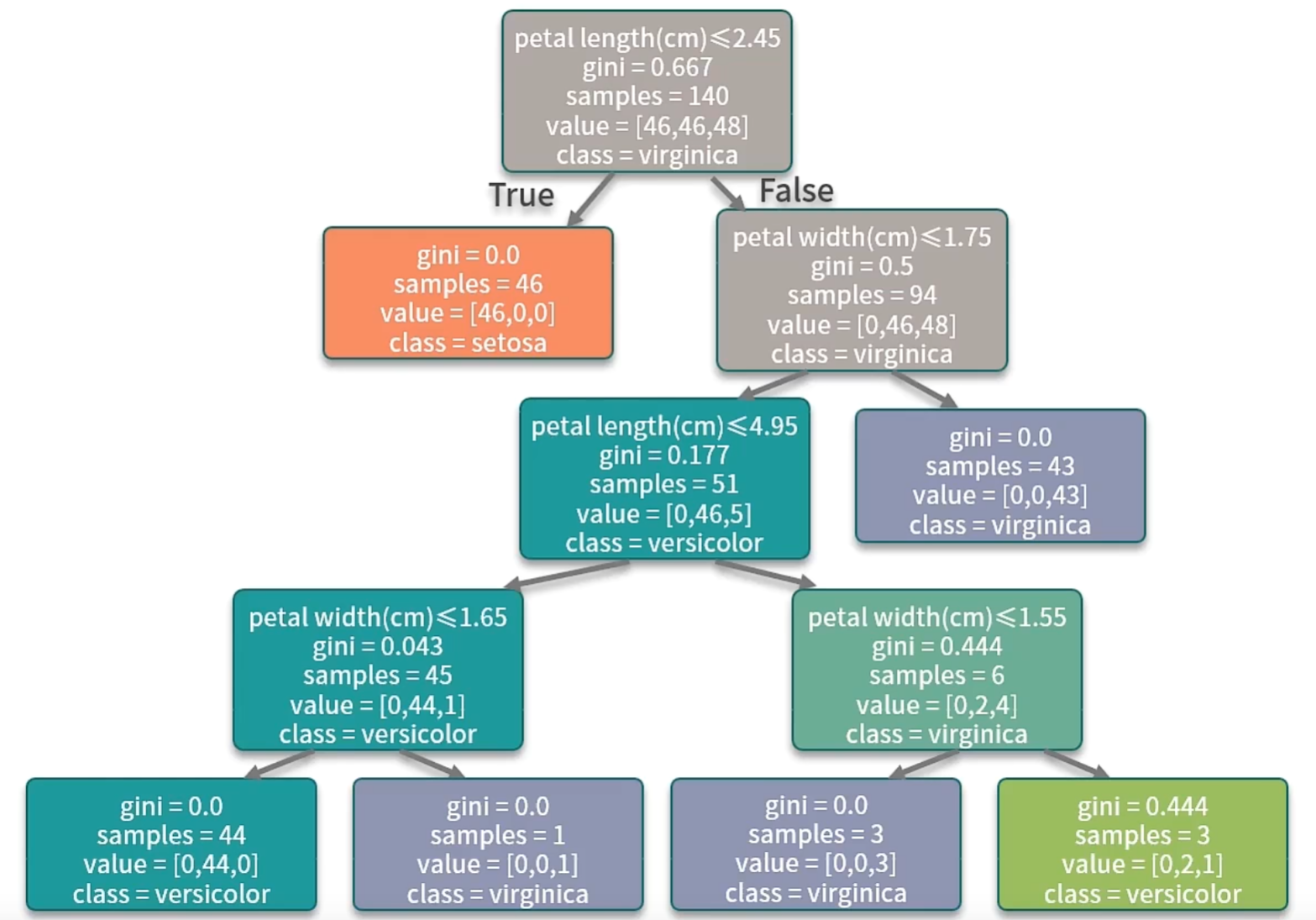
决策树:
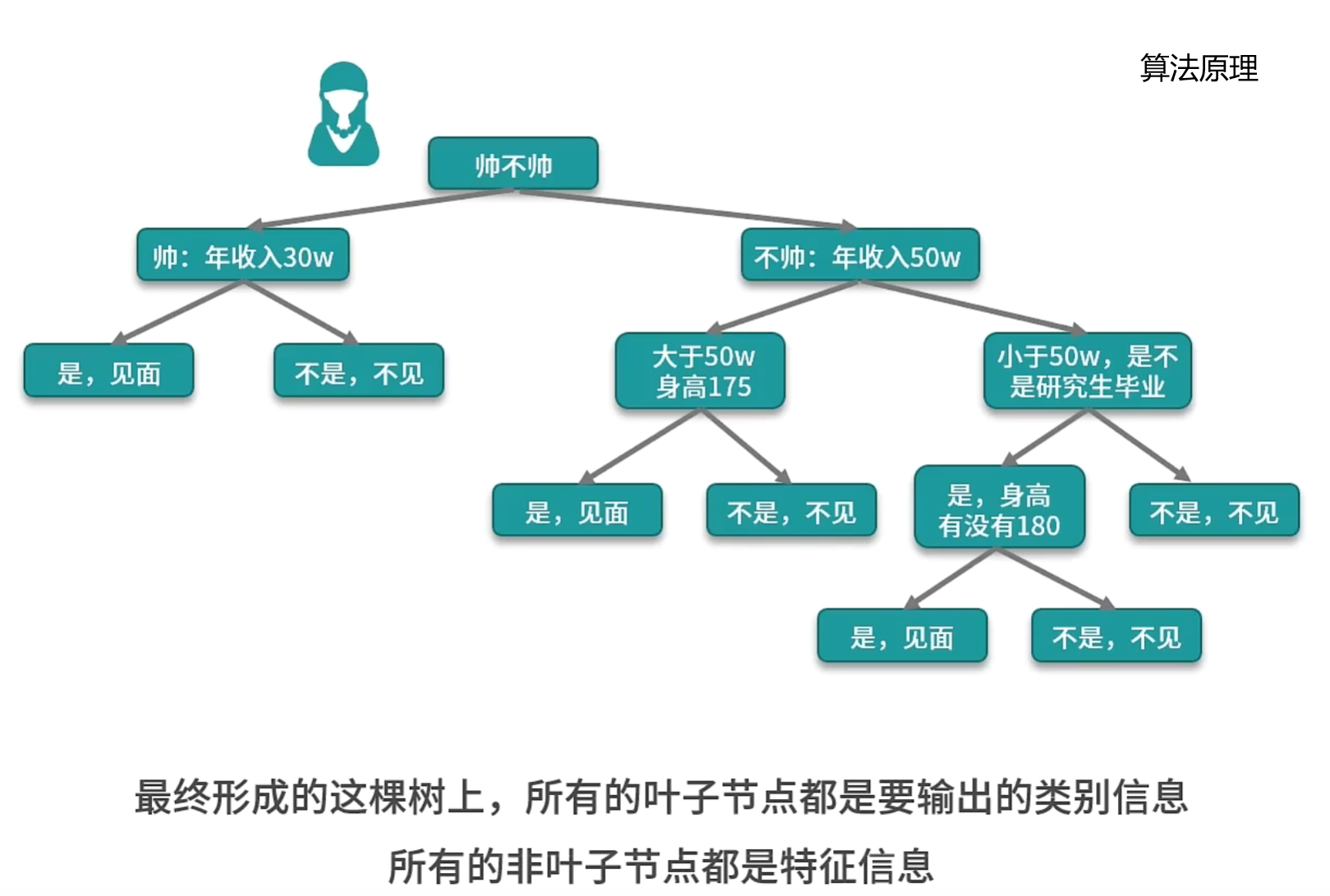
如何选择一个特征作为根节点?下一次决策又该选取哪个特征作为节点?
决策树算法使用信息增益的方法来衡量一个特征和特征之间的重要性。
理想情况:决策树上的每一个叶子节点都是一个纯粹的分类。
实际:决策树实现的时候采用贪心算法,来寻找一个最近的最优解。
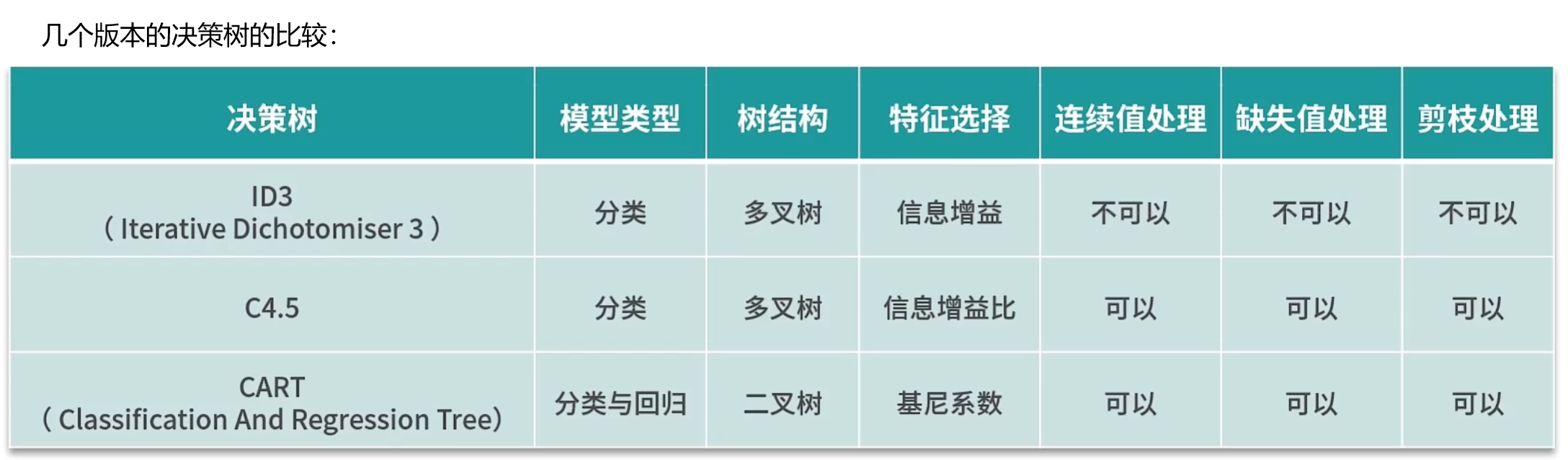
优点:
1.非常直观,可解释性极强。
2.预测速度比较快。
3.既可处理离散值也可以处理连接值及缺失值。
缺点:
1.容易过拟合。
2.需要处理样本不均衡的问题。
3.样本的变化会引发数据结构的巨变。
预剪枝:在决策树构建之初就设定一个阈值,当分裂节点的熵阈值小于设定值的时候就不再进行分裂了。
后剪枝:在决策树已经构建完成以后,再根据设定的条件来判断是否要合并一些中间节点,使用叶子节点来代替。



随机森林:使用bagging方案构建了多棵决策树,然后对所有树的结果来进行平均计算以获得最终的结果。
GBDT:GBDT构建的多棵树之间是有联系的,每个分类器在上一轮分类器的残差基础上进行训练。
XGBoost:优化了GBDT里面的求解过程,并加入了很多工程上的优化项目。